안녕하세요. 루인입니다.
오늘은 배치파일 만들기 강좌를 준비했습니다.
배치파일을 만들기 위해서 필요한 준비물은 메모장(Notepad)입니다.(메모장 버전은 상관없습니다.)
그럼 이제부터 기본적은 배치파일을 만드는법을 알려드리겠습니다.
1. 먼저 메모장(Notepad)을 실행시켜 주세요. *메모장에 아무것도 치지마세요.
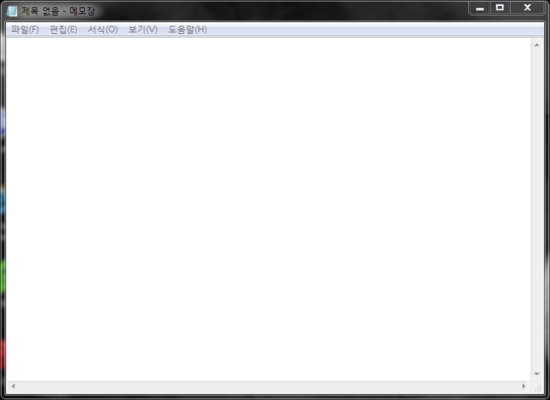
2. 그 다음에 파일에 다른 이름으로 저장을 누르세요.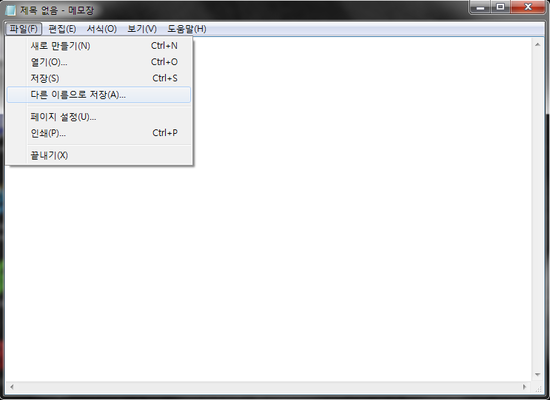
3. 여기부터가 중요합니다. 파일형식을 모든 파일로 바꾸시고 파일이름에는 아무거나 치시면 됩니다.
저는 예제로 a로 하겠습니다. 그리고 a로 하고 저장을 누르시 마시고 a.bat이렇게 .bat를 부쳐주세요. 그리고 저장!!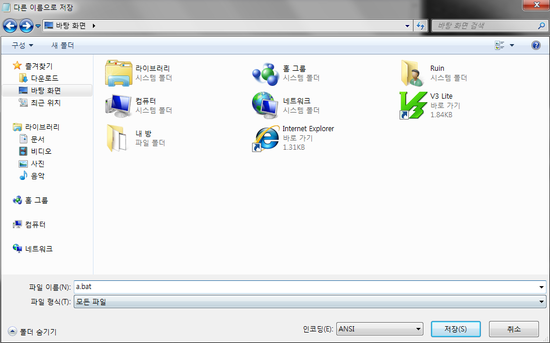
6. 이렇게 만들어 졌습니다. 창안에 톱니바퀴 모양으로 말이죠.
7. 실행을 해볼까요?
그런데 이렇게 오류가 뜬다고요?
이게 정상입니다. 왜냐하면 아무것도 쓰지 않았기 때문입니다.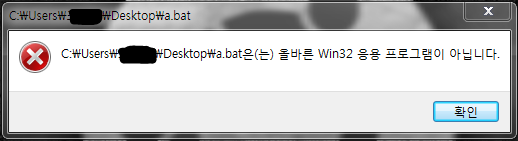
이제 다음 강좌 부터는 이 오류를 안뜨게 하면서 명령어를 넣어보겠습니다.
감사합니다.
'배치파일제작' 카테고리의 다른 글
| 3강. echo 명령어 (0) | 2012.08.22 |
|---|---|
| 2강. @echo on/off (0) | 2012.08.22 |
XML(Extensible Markup Language)을 아시나요?
현재 XML파싱 기법을 알기 전에 XML이 무엇인지 모른다면 아래 사이트를 방문.
XML에 대한 기초적인 정보를 습득하신 후에 보시는 것을 추천합니다.
http://en.wikipedia.org/wiki/XML
위와 같은 XML문서를 Java에서 어떻게 데이터를 가져오는가에 대해 설명을 하고자
이렇게 포스팅을 작성합니다.
API를 보시면 javax.xml.parsers라는 패키지 내에
{
DocumentBuilder
DocumentBuilderFactory
SAXParser
SAXParserFactory
위 4가지의 클래스가 존재하는데 클래스명에서 알수 있듯이 DOM에서는
DocumentBuilder
DocumentBuilderFactory
위 2가지의 클래스로 XML의 데이터를 불러올 수 있습니다.
(물론, me2DAY와 같이 데이터가 큰 경우는 SAX방식이 더 효율적일 수 있습니다)
또, org.w3c.dom 패키지에 있는 Document 클래스도 필요로 합니다.
그럼 파싱할 XML이 필요하겠죠?
미투데이 API를 보니 자신이 적은 글에 대한 xml을 제공합니다.
주소는 http://me2day.net/api/get_posts/미투데이아이디.xml 가 됩니다.
저의 미투데이 아이디는 feato이니.
http://me2day.net/api/get_posts/feato.xml이 되는것이지요.
이제 본격적으로 게시물을 불러오는 프로그램을 만들어보겠습니다.
우선 파싱할 XML의 형태를 분석해야합니다.
<body>티스토리에서는 code block 은 지원되지 않나보네요?</body>
위 코드를 살펴보면 body라는 곳에 포스팅한 글이 출력된다는 것을 확인 할 수 있습니다.
그럼 위 데이터를 출력하는 프로그램을 작성해보도록 합시다.
위에서 확인했던 클래스를 import합니다.
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
그 후 Main Method에 아래와 같이 코드를 작성합니다.
Document me2Day_Document;
DocumentBuilderFactory me2Day_dbf;
// DOM트리를 구성합니다.
me2Day_dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder me2Day_db = me2Day_dbf.newDocumentBuilder();
me2Day_Document = me2Day_db.parse("http://me2day.net/api/get_posts/feato.xml");
// DOM Document에 객체를 가져옵니다.
이때 DOM의 장점이라고 할 수 있는 Node를 불러와야합니다.
Node는 import org.w3c.dom.NodeList; 후 사용이 가능합니다.
위의 클래스를 추가해준 후에 아래와 같이 코딩을 합니다.
NodeList Body = me2Day_Document.getElementsByTagName("body");
아까 위에서 보았던, body라는 태그명으로 데이터를 가져오겠다는 의미가 됩니다.
그러면 반복을 하기전에 해당 노드의 데이터가 몇개인지 확인해야겠지요?
아래와 같이 int형 변수에 Node의 길이를 저장합니다.
int Max_Node = Body.getLength();
그리고 반복을 통해 변화되는 데이터를 가져와야겠지요?
for(int Loop = 0; Loop < Max_Node; Loop++){
}
그럼, 위 반복문 내에는 어떤 코드가 들어가야 할까요?
해당 노트의 엘리먼트를 가져와야하는데 그러기 위해서는 아래 클래스를 추가해야한다.
import org.w3c.dom.Element;
Element클래스의 Method로써 Node.item(Loop)를 Element로 캐스팅한다.
즉, 카운터가 증가할때마다 한칸씩 이동하며, 다른 노드의 데이터를 가져온다.
Text는 역시 import org.w3c.dom.Text;를 추가해준 후 사용할 수 있는데.
XML문서가 이용이 가능한 상태에서는 Text노트를 통해 블록마다 첫번째 자식노드를 가져온다.
즉, Loop가 1일때, Element에 있는 첫번째 노드를 가져오겠다는 의미가 된다.
그 후 String변수를 통해 해당 Text를 getData();만 한다면 이상없이 DOM파싱이 완료된 것입니다.
for(int Loop = 0; Loop < Max_Node; Loop++){
Element Me2DE = (Element)Body.item(Loop);
Text Me2TXT= (Text)Me2DE .getFirstChild();
String Me2Data= Me2TXT.getData();
System.out.println(str);
}
위의 모든 소스코드를 합치면, 이상없이 미투데이의 글이 출력되는 것을 확인할 수 있습니다.
http://kimeunseok.tistory.com/25
그외 참고
===================================================================
http://blog.naver.com/psymarin1/120112814386
=====================================================================
package vvsp.utils;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.w3c.dom.Text;
public class XMLProcessor {
public XMLProcessor() {
// TODO Auto-generated constructor stub
}
public static void main(String[] args) {
// TODO Auto-generated method stub
//File docFile = new File("orders.xml");
Document doc = null;
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// DOM트리를 구성.
DocumentBuilder db = dbf.newDocumentBuilder();
//doc = db.parse(docFile);
doc = db.parse("http://me2day.net/api/get_posts/내아이디.xml");
NodeList body = doc.getElementsByTagName("body");
for(int i=0; i<body.getLength(); i++){
Element element = (Element)body.item(i);
Text text = (Text)element .getFirstChild();
String Me2Data = text.getData();
System.out.println(Me2Data);
}
} catch (javax.xml.parsers.ParserConfigurationException pce) {
System.out.println("The parser was not configured correctly.");
System.exit(1);
} catch (java.io.IOException ie) {
System.out.println("Cannot read input file.");
System.exit(1);
} catch (org.xml.sax.SAXException se) {
System.out.println("Problem parsing the file.");
System.exit(1);
} catch (java.lang.IllegalArgumentException ae) {
System.out.println("Please specify an XML source.");
System.exit(1);
} catch (Exception e) {
System.out.print("Problem parsing the file: "+e.getMessage());
}
}
}
'ApplicationPrograming > Java' 카테고리의 다른 글
| Commons-DbUtils (0) | 2013.03.15 |
|---|---|
| Commons-Fileupload의 한글관련 문제 추가 (0) | 2013.03.15 |
| JDOM (0) | 2013.01.31 |
| 랜덤 숫자 생성 (0) | 2012.06.11 |
| jar파일 실행 (0) | 2012.05.04 |
금일 이클립스로 JSP 페이지 작업 중, 잘 사용해왔던 코드 어시스트 기능이 JSP 코드에서는 되지 않는 걸 확인하였다!! (하단 그림 참조)
request.getParameter()를 매번 직접 타이핑 것도 은근 시간이..ㅜ.ㅜ

다른 것들은 다 되는데 이것만 안되는 것은 분명 문제가 있고, 문제가 있는 것이면 당연히 그 해결책도 있을 것으로 보고..
확인해보니 문제는 바로 라이브러리가 자동으로 등록이 되지 않아 JSP 관련 소스만 코드 어시스트 기능이 되지 않는 것을 확인할 수 있었다.
[해결책]
해당 라이브러리 수동 적용 방법은,
프로젝트 -> Properties -> Java Build Path -> Add External JARs -> {Tomcat폴더}/lib/Servlet-api.jar 추가 (하단 그림 참조)
* 프로젝트 별로 수동으로 설정을 해줘야할 것으로 보이기 때문에, 조금은 번거로울 수 있겠다.

* 수동 추가 후 코드 어시스트 목록에 뜨는 메소드 확인!
- 문제 없이 잘 올라오는 것을 확인할 수 있다!^_^

'Tool > Eclipse' 카테고리의 다른 글
| 이클립스 톰캣 제거 후 재 설정 안될때 (0) | 2015.05.19 |
|---|---|
| 이클립스 버젼 정리 (0) | 2014.01.28 |
| eclipse에서 jquery script validate 오류 해결 (0) | 2012.09.24 |
| Visual Editor 간단 사용법 (0) | 2012.03.29 |